在前端获取UTC时间戳的方法
1 | function getUtcTimestamp() { |
1 | function getUtcTimestamp() { |
SteemPower 平时都被叫做 SP,这个单位虽然我们经常见,但是这个并不是真正的资产。
SP 的背后其实是 VestingShares。鉴于 Steem 的通胀,SP其实是用来表示当前你持有的 VestingShares 价值多少 Steem 的单位。
VestingShares 我们把他看做一个商品会更容易理解。
用 Steem 币购买 VestingShares 的过程就是 PowerUP,相对的,卖出 VestingShares 得到 Steem 币的操作就是 PowerDown。
而购买价格就是 total_vesting_shares 和 total_vesting_fund_steem 的比值,
之所以价格这样计算,是因为系统要求,当用户 PowerUp 的时候,要求 total_vesting_shares / total_vesting_fund_steem 比值不变。
即 total_vesting_shares / total_vesting_fund_steem = (total_vesting_shares + delta_vesting_shares) / (total_vesting_fund_steem + delta_vesting_fund_steem)
其中 delta_vesting_fund_steem 就是我们要 PowerUp 的 Steem,我们需要知道能获取多少 vesting_shares,即 delta_vesting_shares。
整理一下就是 delta_vesting_shares = (total_vesting_shares / total_vesting_fund_steem) * delta_vesting_fund_steem
由此得到价格关系。
相关代码:https://github.com/steemit/steem/blob/0.23.x/libraries/chain/database.cpp#L1199-L1314
total_vesting_fund_steem 这个池子除了上面提到的 PowerUp 操作会增加这个池子,还有就是每次出块会增加。
每次出块,每个块总产出 Steem 的 15% 会进入到 total_vesting_fund_steem。
而 total_vesting_shares 的增加来源于见证人收益,因为每个块的见证人收益(即不到10%的块总产出)是以 VestingShares 发放,而不是以 Steem 发放。
发放见证人收益的时候,会同时增加 total_vesting_fund_steem 和 total_vestting_shares。
综上两点,就意味着 total_vesting_fund_steem 增长速度会快于 total_vesting_shares,也就是说 vesting_shares 会越来越值钱。
而 SP 的意义目前也就是实时展示你持有的 VestingShares 现在值多少 Steem。你如果不在这个时刻 PowerDown,那么这个 SP 就是没有意义的,只是一个数字。
如果说 SP 只是为了实时表示 VestingShares 的 Steem 价值,那么 SP 这个概念可能是个很失败的引入。
为了方便查看相关的系统参数和变量,我写了一个工具,文章中提到的参数都可以在工具中看到。
工具地址:https://dev-tools.steem.fans/
steem 的通胀率是按照规律线性递减的,直到达到设置的值,通胀率就不会再减小了。
通胀率如何计算?
通胀率从 STEEM_INFLATION_RATE_START_PERCENT(978)开始,到 STEEM_INFLATION_RATE_STOP_PERCENT(95)结束。
即从 9.78% 到 0.95%。其中递减率是每 STEEM_INFLATION_NARROWING_PERIOD(250000)块减少 0.01%。
公式:
1 | current_inflation_rate = max( STEEM_INFLATION_RATE_START_PERCENT - head_block_num / STEEM_INFLATION_NARROWING_PERIOD, STEEM_INFLATION_RATE_STOP_PERCENT ) |
通胀是针对现有供应量来算的,所以每年新增的STEEM数量按照当前所在的25万块这个区间的通胀率算的话是:
1 | virtual_supply * current_inflation_rate |
由于每3秒出一个块,所以理论上如果不丢块,每年出块数量为 STEEM_BLOCKS_PER_YEAR(即 6060243653),
进而当前25万块区间内,每个块的理论产出为:virtual_supply * current_inflation_rate / STEEM_BLOCKS_PER_YEAR
按照当前写文章时间的高度(45429466)算出来的块理论产出STEEM数量为 EachBlockRewardInTheory = 2.944 STEEM 。
相关代码:https://github.com/steemit/steem/blob/0.23.x/libraries/chain/database.cpp#L2396-L2403
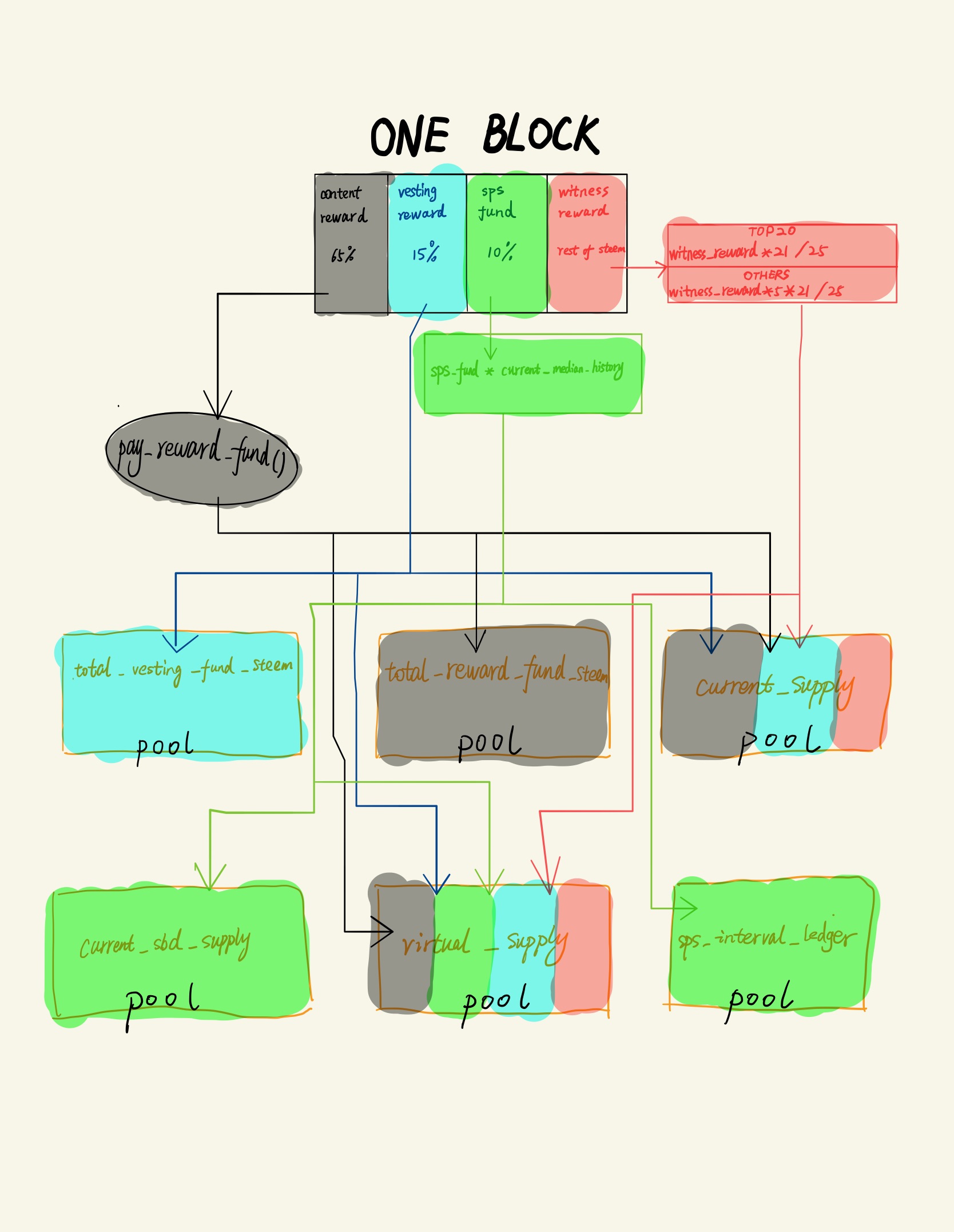
总的来说,每个块是按照 65% content reward, 15% vesting_reward, 10% SPS fund, 10% witness reward。
按照上边的例子,分别得到
1 | content_reward = EachBlockRewardInTheory * 0.65 = 1.913 STEEM |
注意:
这里在 HF17 之后有这样的操作,new_content_reward = pay_reward_funds( content_reward ),
目前 pay_reward_funds 没看懂,我的工具暂时定义 new_content_reward = content_reward 。
另外,见证人收益不是直接乘以 10%,而是减出来的,即
1 | witness_reward = EachBlockRewardInTheory - new_content_reward - vesting_reward - sps_fund |
如此便得到最初的四项分配值。
之后还需要进行一些计算和分类,来最终把块产生的STEEM加入到各个池子中。
其中,需要先处理见证人的收益。
见证人分为TOP20(Elected)和非TOP20(TimeShare),两者的权重(weight)不同。
见证人的最终收益计算公式:
1 | new_witness_reward = witness_reward * STEEM_MAX_WITNESSES * weight / witness_pay_normalization_factor |
其中 STEEM_MAX_WITNESSES 为 21,witness_pay_normalization_factor 为 25.
TOP20的权重(elected_weight)为 1,非TOP20的权重(timeshare_weight)为 5.
除了见证人外,对于 sps_fund_reward 也需要单独计算,因为 SPS 最终是以 SBD 为单位,而块产生的是STEEM,所以需要进行转换。
转换率来自喂价,即 current_median_history。最终公式为:
1 | sps_sbd = sps_fund_reward * current_median_history |
这个时候,所有的计算工作基本结束,开始对数据进行写入操作,也就是进入各个池子,
1 | total_vesting_fund_steem += vesting_reward |
最后一步,把 new_witness_reward 以 vesting_shares 的形式发放给见证人。 vesting_shares 就是 SP 的实质。
相关代码:https://github.com/steemit/steem/blob/0.23.x/libraries/chain/database.cpp#L2404-L2453
最后是我画的产出STEEM流向图:
1 | awk '{print $1}' access.log | sort -n | uniq | wc -l |
1 | grep "07/Apr/2017:0[4-5]" access.log | awk '{print $1}' | sort | uniq -c| sort -nr | wc -l |
1 | awk '{print $1}' access.log | sort -n |uniq -c | sort -rn | head -n 100 |
1 | awk '{print $1}' access.log | sort -n |uniq -c |awk '{if($1 >100) print $0}'|sort -rn |
1 | grep '104.217.108.66' access.log |awk '{print $7}'|sort |uniq -c |sort -rn |head -n 100 |
1 | awk '{print $7}' access.log | sort |uniq -c | sort -rn | head -n 100 |
1 | grep -v ".php" access.log | awk '{print $7}' | sort |uniq -c | sort -rn | head -n 100 |
1 | cat access.log | cut -d ' ' -f 7 | sort |uniq -c | awk '{if ($1 > 100) print $0}' | less |
1 | tail -1000 access.log |awk '{print $7}'|sort|uniq -c|sort -nr|less |
1 | awk '{print $4}' access.log |cut -c 14-21|sort|uniq -c|sort -nr|head -n 100 |
1 | awk '{print $4}' access.log |cut -c 14-18|sort|uniq -c|sort -nr|head -n 100 |
1 | awk '{print $4}' access.log |cut -c 14-15|sort|uniq -c|sort -nr|head -n 100 |
在nginx log中最后一个字段加入$request_time
1 | cat access.log|awk '($NF > 3){print $7}'|sort -n|uniq -c|sort -nr|head -20 |
1 | cat access.log|awk '($NF > 1 && $7~/\.php/){print $7}'|sort -n|uniq -c|sort -nr|head -100 |
1 | grep 'Baiduspider' access.log |wc -l |
1 | grep 'Baiduspider' access.log |grep '404' | wc -l |
1 | netstat -tan | grep "ESTABLISHED" | grep ":80" | wc -l |
1 | tcpdump -i eth0 -tnn dst port 80 -c 1000 | awk -F"." '{print $1"."$2"."$3"."$4}' | sort | uniq -c | sort -nr |
鉴于 Steem 的见证人节点和全节点 replay 的时间很长,所以有必要即使把 replay 好的数据进行备份。
这样一旦出现数据损坏的情况,能最快速度从灾难中完成恢复。
另外,部署新的节点的时候,也可以节省大量的时间。
经过我两天的搜索,最终找到了一台加拿大的廉价大硬盘主机。
1 | Horse Storage Offer |
有感兴趣的可以点击这里看看 ,找一下 special order 里面有一款叫做 Horse Storage Offer。
经过一番安装部署,现在已经上线。
目前还在上传备份数据过程中。
昨天发文说到 我上线了一个Steem数据服务,但是 Nginx 自带的 autoindex 功能的 UI 实在是丑爆了,那么怎么美化一下呢?
经过研究发现了三种方案。
在 Nginx 的配置中,有下面这两个配置项目:
1 | add_before_body /xxx/file1.html; |
这两个选项,可以在 Nginx 输出 HTML 之前和之后分别先输出你设定的文件。
这样我们可以在自定义我们的头部或者尾部,加入我们自己想要的样式表或者用 js 实现更牛逼的功能。
完整的配置大概是这样
1 | location / { |
这里需要注意的是这两个参数的寻址,是基于
root配置项的,也就是在上面的示例中,.beauty目录是在/data/wwwroot/steem目录下面的。另外,如果你的自定义文件里有包含css和js文件,还需要有try_files参数配合一下。
这个功能唯一的不好处就是在查看网页源代码的时候,发现这两个参数的插入位置是在原来 <html> 之前和 </html> 之后。
这就让有代码洁癖的人感到很恶心。。。
该方案是第三方开发的插件:https://www.nginx.com/resources/wiki/modules/fancy_index/ 。
鉴于我使用的是 Docker 版的 Nginx,要想安装个第三方插件,我还要自己编译打包,很麻烦,所以这个方案就没有尝试。
不过看文档说明,应该是跟方案一思路一样,只不过多加了几个注入位置吧。
目前,我使用的是方案三。这个方案则是依赖的 Nginx 的这个参数 autoindex_format。
这个参数可以规定输出信息格式,默认是 html,我们可以设置这里为 json。这样就变成了一个 api 接口。
然后自己去开发一套自己喜欢的前端,调用这个 api 接口就可以了。
这里我从网上找了一套现成的 UI 来使用,地址:https://github.com/spring-raining/pretty-autoindex 。
在 Nginx 配置这块,我没有按照这个库的方法配置两个 Server 模块,我是分成了两个 location 来实现。
参考配置如下:
1 | location / { |
通过 alias 实现 /data 为 api 接口,来获取目录结构信息。
经过一下午的折腾,最终终于让 autoindex 页面看上去不是那么丑了,并且还加入了 Google Analytics。
以后如果还有什么想搞的好玩的东西,也可以加入到里面了。
最近在看官方库的Dockerfile相关的脚本,学习到了一些有价值的点。
比如在区块数据备份这块,我发现官方使用的 lz4 压缩工具。
去查了下,发现 lz4 是目前综合来看效率最高的压缩算法,更加侧重压缩解压速度,压缩比并不是第一。在当前的安卓和苹果操作系统中,内存压缩技术就使用的是 lz4 算法,及时压缩手机内存以带来更多的内存空间。本质上是时间换空间。
压缩效率高,对于像 steem 这样的庞大的数据怪物的备份来说,太重要了。
使用起来也很方便,系统应该都是默认安装了 lz4 的。
在目的目录执行下面的命令:
1 | tar -cf steem_blockchain.tar.lz4 --use-compress-program=lz4 -C /data2/steem/data/witness_node_data_dir blockchain/ |
就可以把 /data2/steem/data/witness_node_data_dir 下面的 blockchain 文件夹打包并使用 lz4 压缩。
经过测试,源目录 blockchain 的大小是 374G,压缩后的文件是 261G,压缩比还可以。
最重要的是时间。往常在我的服务器上使用 gzip 和 tar 打包备份,一般就是大半天的时间。而这次使用 lz4 压缩才用了大约两个小时,太惊艳了!
接下来,要把目前所有的备份都换成使用 lz4 进行压缩打包。
在steem链上注册有三种途径,account_create,create_claimed_account和account_create_with_delegation,不过,最后这个 account_create_with_delegation 已经不再建议使用了。所以目前主要是通过 account_create 和 create_claimed_account 两个方法来注册新用户。
这个接口使用很简单,只需要交钱就能注册,即花费 steem 代币。
使用方法: https://developers.steem.io/apidefinitions/#broadcast_ops_account_create
这个接口注册用户需要配合 claim_account 来进行。需要使用 claim_account 先花费 RC 申请一个牌子,然后再消耗牌子去使用 create_claimed_account 注册用户。
claim_account 使用方法: https://developers.steem.io/apidefinitions/#broadcast_ops_claim_account
create_claimed_account 使用方法: https://developers.steem.io/apidefinitions/#broadcast_ops_create_claimed_account
这里给出一下 claim_account 的 demo:
1 | const steem = require('steem'); |
无论那个接口注册用户,都要涉及到注册费用,只不过 account_create 是直接花费注册费用,而 create_claimed_account 途径注册用户,需要计算消耗多少 RC。
目前使用 account_create 注册用户会消耗当前用户 3 steem 代币。那么这个数是从哪里获得的呢?
我们看下面的代码:
1 | FC_ASSERT( o.fee == wso.median_props.account_creation_fee, "Must pay the exact account creation fee. paid: ${p} fee: ${f}", |
上面的代码来自
/libararies/chain/steem_evaluator.cpp中的void account_create_evaluator::do_apply( const account_create_operation& o )。
代码位置: https://github.com/steemit/steem/blob/master/libraries/chain/steem_evaluator.cpp#L331
可以看到在注册费这里需要断言,注册费用为 wso.median_props.account_creation_fee。
这个 wso 联系上下文看到是 _db.get_witness_schedule_object(),可以知道是拿的见证人的信息。其中里面涉及到一个 median_props 的成员,需要看看如何实现(看字面意思是中位数)。
1 | /// sort them by account_creation_fee |
上面的代码来自
/libararies/chain/witness_schedule.cpp中的void update_median_witness_props( database& db )。
位置在: https://github.com/steemit/steem/blob/master/libraries/chain/witness_schedule.cpp#L37
其中 active 联系上下文,可以知道拿到的是当前活跃的所有见证人(目前的配置是21位),然后对这些活跃的见证人配置中的 account_creation_fee 进行排序,然后取中位数。
结论:如果想要变动注册费用,需要半数以上的活跃见证人同时调整自己的 account_creation_fee 配置。
关于 create_claimed_account 和 claim_account 这两个函数,目前还没有完全看完,因为其中还涉及到了 RC 部分的代码。
目前还不清楚要扣除的RC的计算公式或者说方法。当前只是了解到在使用 claim_account 的时候的几个限制条件。
1 | if( o.fee.amount == 0 ) |
上面的代码来自
/libararies/chain/steem_evaluator.cpp中的void claim_account_evaluator::do_apply( const claim_account_operation& o )。
位置在: https://github.com/steemit/steem/blob/master/libraries/chain/steem_evaluator.cpp#L3211
在代码中,我们能看到有两个数量上的限制:
current_witness.available_witness_account_subsidiesgpo.available_account_subsidies其中还涉及到一个全局参数 STEEM_ACCOUNT_SUBSIDY_PRECISION。
上面这三个值,我们通过下面的代码可以快速的获取到:
1 | steem.api.getActiveWitnesses(function(err, result) { |
我们用 @justyy 提供的网页工具 可以快速的看到结果。
目前的结论就是,使用 RC 注册用户,不仅受到你自身 RC 数量影响,还会受到当前出块见证人的余量(available_witness_account_subsidies),以及全局的余量(available_account_subsidies) 两个值的限制。具体这两个值怎么恢复,以及申领一个牌子消耗多少RC的计算,等我读完 RC Plugin 的代码应该就可以搞明白了。
目前这里没有细看,但是可以看到费用是流向了 @null 账号。在最终的写入区块的操作的时候,也有对 @null 账号的单独处理,
截取一段代码如下:
1 | case STEEM_ASSET_NUM_STEEM: |
上面的代码来自
/libararies/chain/database.cpp中的void database::adjust_supply( const asset& delta, bool adjust_vesting )。
位置在: https://github.com/steemit/steem/blob/master/libraries/chain/database.cpp#L4689
其中 delta 就是要扣除的手续费,props 是 dynamic_global_property_object。可以看到是对整个系统的供应做了修改,但是具体如何修改,由于这里涉及的条件很多,还没有理顺清楚。
最后列出一下还没有搞清楚的事情:
available_witness_account_subsidies 和 available_account_subsidies 这两个限制条件外,对于使用 RC 申请牌子是否还有其他的限制条件。available_witness_account_subsidies 和 available_account_subsidies 这两个值如何恢复。今天在开发 Steem Watcher 过程中,由于需要跑计划任务,所以研究了一下如何在容器环境下使用 crond。
在此之前,我曾经使用宿主机的 crond 来启动一个临时容器跑任务,但这个思路很糟糕,并不方便快速移植。于是考虑还是要基于容器内部进行计划任务才是终极方案。
由于我的 Steem Watcher 使用的镜像是我自己基于 alpine 编译的,而 alpine 中已经带有 crond 程序,所以要在容器里实施计划任务还是比较轻松。
我们可以先看下 crond 的参数说明
1 | /app # crond -h |
介于容器执行命令不能立即返回,所以我们需要使用 -f 参数让 crond 在前台运行,这样可以保持容器一直运行。
然后查了下手册,发现 crond 的配置文件在 /etc/crontabs/ 目录下面。这里需要注意,由于每个用户的 crontab 是独立的,如果你是 root 用户启动,那么其配置文件为 /etc/crontabs/root。
弄明白这些之后,我们想要搞计划任务的话,只需要创建个容器,让其 command 命令是 crond -f,然后把一个配置好的文件 mount 到容器里的 /etc/crontabs/root,再把需要执行的程序 mount 进去,最后启动即可了。
具体可以参考 https://github.com/ety001/steem-watcher/blob/master/docker-compose.yml#L28 这里了解。
除此之外还需要 额外注意的事情 就是,如果通过挂载的方式覆盖
/etc/crontabs/root,那么在宿主机上的配置文件,需要配置为755权限,并且用户和用户组需要设置为root。
项目地址: https://github.com/ety001/steem-watcher
该项目基于之前项目的程序修改而来,目的是为了可以定制化监控链上数据.
目前只监控 claim_account, create_claimed_account, account_create 三种数据.
如果你想监测更多类型数据,请自行修改
bin/lib/opType.py
由于使用了 docker 技术,整个部署过程非常简单。
1 | git clone https://github.com/ety001/steem-watcher.git |
1 | cd steem-watcher |
参数说明:
1 | STEEMD=https://api.steemit.com # 节点地址 |
1 | ./start.sh |
1 | ./logs.sh |
1 | ./stop.sh |
crontab 配置文件在 config/crontab,需要用 root 权限修改crontab 日志在 ./logs 目录下sudo rm -rf db/*提 Issue 或者 发邮件给我: work@akawa.ink